Communications of the ACM
Yes, Computer Scientists Are Hypercritical

Are computer scientists hypercritical? Are we more critical than scientists and engineers in other disciplines? Bertrand Meyer's August 22, 2011 The Nastiness Problem in Computer Science blog post partially makes the argument referring to secondhand information from the National Science Foundation (NSF). Here are some NSF numbers to back the claim that we are hypercritical.
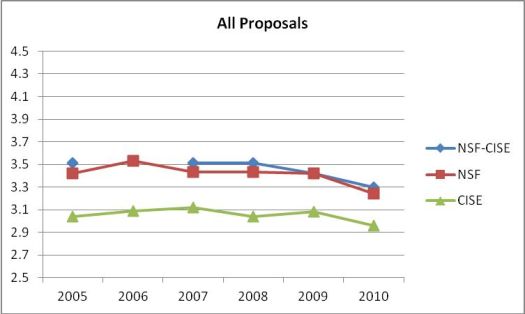
This graph plots average reviewer ratings of all proposals submitted from 2005 to 2010 to NSF overall (red line), just Computer & Information Science & Engineering (CISE) (green line), and NSF minus CISE (blue line). Proposal ratings are based on a scale of 1 (poor) to 5 (excellent). For instance, in 2010, the average reviewer rating across all CISE programs is 2.96; all NSF directorates including CISE, 3.24; all NSF directorates excluding CISE, 3.30.
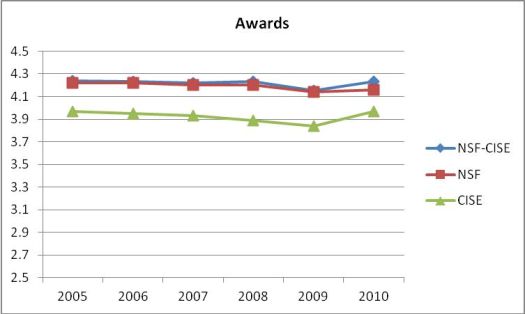
Here are the numbers for just awards (proposals funded)
and just declines (proposals not funded):
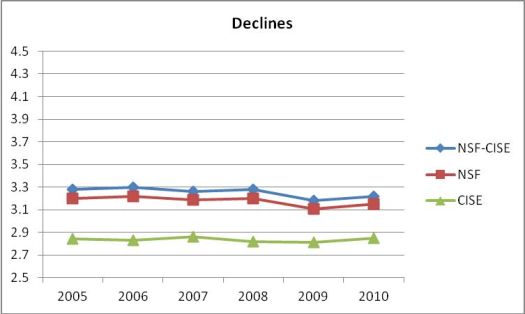
The bottom-line is clear: CISE reviewers rate CISE proposals on average .41 points below the ratings by reviewers of other directorates' proposals. The difference is a little better (.29 points) for awards and a little worse (.42 points) for declines.
How does our hypercriticality hurt us? In foundation-wide and multi-directorate programs, CISE proposals compete with non-CISE proposals. When a CISE proposal gets "excellent, very good, very good" it does not compete well against a non-CISE proposal that gets "excellent, excellent, excellent" even though a "very good" from a CISE reviewer might mean the same as an "excellent" from a non-CISE reviewer. In what foundation-wide programs can this hurt us? Some long-standing ones include: Science and Technology Centers (STC), Major Research Instrumentation (MRI), Graduate Research Fellowship (GRF), Integrative Graduate Education and Research Traineeship (IGERT), Partnerships for International Research and Education (PIRE), and Industry/University Cooperative Research Centers (I/UCRC). Some recent cross-foundational initiatives include: Cyber-enabled Discovery and Innovation (CDI); Science, Engineering, and Education for Sustainability (SEES); and Software Infrastructure for Sustained Innovation (SI2). Some recent multi-directorate initiatives include: National Robotics Initiative (NRI) and Cyberlearning Transforming Education (CTE). The one that was most painful for me when I was CISE AD was the annual selection from among NSF CAREER awardees of those whom the Director of NSF would nominate for the Presidential Early Career Awards for Scientists and Engineers (PECASE). To the foundation-level selection committee, I remember having to make forceful arguments for CISE's top CAREER awardees because they had "very good”s among their ratings, whereas all other directorates' reviewer scores for their nominees were "excellent”s across the board. What is the Director of NSF to do when deciding the slate of nominees to forward to the President?
Fortunately—or not—word had gotten around sufficiently within NSF: The CISE community is known to rate proposals lower than the NSF average. So my job was to continually remind the rest of the foundation and the Director about this phenomenon. It's merely a reflection of our hypercriticality, not a reflection of the quality of the research we do.
Why are we so hypercritical? I have three hypotheses. One is that it is in our nature. Computer scientists like to debug systems. We are trained to consider corner cases, to design for failure, and to find and fix flaws. Computers are unforgiving when faced with the smallest syntactic error in our program; we spend research careers on designing programming languages and building software tools to help us make sure we don't make silly mistakes that could have disastrous consequences. It could even be that the very nature of the field attracts a certain kind of personality. The second hypothesis is that we are a young field. Compared to mathematics and other science and engineering disciplines, we are still asserting ourselves. Maybe as we gain more self-confidence we will be more supportive of each other and realize that "a rising tide lifts all boats." The third hypothesis is obvious: limited and finite resources. When there is only so much money to go around or only so many slots in a conference, competition is keen. When the number of researchers in the community grows faster than the budget—as it has over the past decade or so—competition is even keener.
What should we do about it? As a start, this topic deserves awareness and open discussion by our community. I'm definitely against grade inflation, but I do think we may be giving the wrong impression about the quality of our proposals, the quality of the researchers in our community, and the quality of our research. For NSF, I have one concrete suggestion. When one looks at reviews for proposals submitted to NSF directorates other than CISE, while the rating might say "excellent" the review itself might contain detailed, often constructive criticism. When program managers make funding decisions, they read the reviews, not just the ratings. So one idea is for us to realize that we can still be critical in our written reviews but be more generous in our ratings. I especially worry that unnecessarily low ratings or skimpy reviews discourage good people from even submitting proposals let alone pursuing good ideas.
It's time for our community to discuss this topic. Data supports the claim that we are hypercritical, but it is up to us to decide what to do about it.
Please note these caveats about the numbers: (1) The spreadsheet from which I took these numbers has an entry for "NSF overall" and for each directorate. I derived the NSF-CISE numbers not using the "NSF overall" number, but rather subtracting the CISE number from the total of all directorates. This led to a small discrepancy in some of the numbers in the "NSF-CISE" numbers, but does not affect the bottom-line conclusion. (2) There is a lot of averaging of averages in these numbers. The "Awards" number for CISE, for example, represents the average of the average scores across all CISE programs, and similarly for the "Declines." Looking across all NSF (and similarly CISE) programs, there is a wide variation in ratings and a wide range in the numbers of proposals submitted (and similarly awarded or declined). (3) Since I no longer have access to the raw data and my spreadsheet lacks comments, I cannot readily explain the discrepancies noted in (1) or how some of the numbers in the spreadsheet were calculated. I showed the 2010 numbers to the CISE Advisory Committee at the May 2010 meeting, pointing out that data for 2005-2009 are similar.
Comments
Anonymous
Another way to address the problem is to change the system so that reviewers do not provide absolute ratings of proposals, but rather provide comparative rankings of proposals. This eliminates the effect of each reviewer's general tendency towards hypo- or hyper-criticality
I wrote a paper on this very piont a few years ago:
http://research.microsoft.com/apps/pubs/default.aspx?id=80226
John Douceur
Microsoft Research
Anonymous
I can't believe the shoddy statistical analysis passed off here as "scientific research". In this day and age it is astounding that someone would show only averages for CISE and non-CISE, without doing a Student's t test or Mann-Whitney-Wilcoxon test to see whether the result is statistically significant. The conclusion validity of the work is almost nil. Maybe if we reject this blog post, the author will get the message and do better work in her next post.
--Jamie Andrews
University of Western Ontario
(yes, I am joking)
Anonymous
what is the distribution / curves for the other non-CISE disciplines? is CISE really that much of an outlier, or is there quite a range?
Anonymous
What about the hypothesis that CISE proposals actually deserve these ratings? We can't eliminate this just because it would not be convenient for us.
Anonymous
Doesn't it just show that comparing numeric scores of reviewers across disciplines and even within a program committee meeting is pointless?
Anonymous
I would also like to know how the other research scored. Is CISE an outlier?
Anonymous
One of the main causes for this is the CS emphasis on highly selective conferences. In CS, everything you ever do is subject to the filter of fierce competition. Everything is a zero-sum game, and everyone ends up having good papers rejected. Since authors are also reviewers, the acceptance threshold is continuously going up. Eventually, only outstanding contributions are good enough, and even the significance of those can be fiercely debated at program commitee meetings. Obviously, this spills over to proposal evaluation. The only way to eliminate this problem is to abolished these highly selective conferences. Science has worked great without them for 500 years, they are doing more harm than good. Let conferences be conferences (i.e. a place to just talk about stuff) and rely on journals for high selectivity. The journal reviewing process does not have the problems of conference reviewing.
Anonymous
My hypothesis is that 10-20 years ago Computer Science researchers only had to compete against other CS researchers, generally for targeted funding. Being "hypercritical" of other research meant your research (or your subdiscipline, or your collaborators/friends) was more likely to get funding. These days, CS no longer has targeted funding, rather it's just another discipline in the general science & engineering funding mix.
Clearly our learned behavior is no longer appropriate in this context, when we are competing against a much wider pool.
James Noble
The only way to eliminate this problem is to abolished these highly selective conferences... The journal reviewing process does not have the problems of conference reviewing.
Oh come on. Inasmuch as the "problem" is selectivity, then highly selective journals are just as bad as highly selective conferences. Talk to Physicists about Letters to Nature, or PRLs, about the difficulty of refereeing on a one week deadline, about squeezing references down so their paper fits on two or four pages with citations being nothing but first author, journal, page number --- and as a result, the active researchers look far more to informal web "archives" than anything a librarian would consider "archival".
I don't think researchers are any less competitive in Physics or Biology (or English Lit. for that matter). The difference is that other disciplines have decades of experience in "fighting their corner", whereas for whatever reason, we Computer Scientists act as if that is beneath us.
For better or for worse, Computer Science came of age after the 747 - and our conference based-publication structure reflects that as much as anything.
Yannis Smaragdakis
I'm very happy to see the data reported as "hypercriticality" instead of nastiness. We are indeed hypercritical, and it's perfectly explainable.
Conjecture: there is no nastiness problem, just a confluence of two inherent factors. First, we are an area that focuses (more than others) on conceptual novelty. Second, there is very rarely something conceptually new in CS, especially in applied directions and especially at the proposal (and not paper) level.
In support of the conjecture:
-I've seen a lot of Physics reviews. (My wife is a physicist.) They are by no means more "professional" than in CS. If nothing else, they are nastier.
-Our area itself has trained us to analyze everything and focus on conceptual novelty. We have thinking processes that let us distill everything and then compose it in complex ways. "Software is distilled complexity", etc.
-It is really hard to have conceptual novelty in most areas of computer science. Even the most celebrated ideas are similar at the high-level to something that has been done before. The interesting "twist" is always low-level. For proposals, this is deadly, because there can be no proof (e.g., experiments or new algorithms) that what one does is indeed new. People have to rely on high-level intuitions. This is not the case in other sciences. When one says "I will use this kind of biological mechanism to explain/influence this kind of real-life phenomenon", there is no doubt about conceptual novelty. Either this has been done before or not. The only question is whether it's believable that it is feasible and whether the PI is the best person to do it.