Communications of the ACM
We Should Stop Saying 'Language Independent.' We Don't Know How To Do That

Allison Elliott Tew and Miranda Parker developed the first validated measures of CS1 knowledge that worked (i.e., measured essentially the same) for students regardless of whether they studied Python, MATLAB, or Java in their introductory course. The main two papers are these:
- "The FCS1: a language independent assessment of CS1 knowledge." (See paper here.) This is where Allison presented the main product of her dissertation work. This was the first time that we had a carefully validated test for research purposes that worked across these three common CS1 languages. The test itself is in a pseudocode that has elements of all three programming languages in it. The FCS1 was later used in the ITICSE Working Group report: "A fresh look at novice programmers' performance and their teachers' expectations." (see paper here).
- "Replication, Validation, and Use of a Language Independent CS1 Knowledge Assessment." (See paper here.) Miranda Parker replicated the FCS1 (which had not been done previously with a validated CS assessment) in order to have an instrument that could be freely shared with anyone. It’s been more successful than we might have guessed, with four papers using the SCS1 presented at the latest ACM SIGCSE Technical Symposium, including a fascinating analysis of the SCS1 by Benji Xie and colleagues, "An Item Response Theory Evaluation of a Language-Independent CS1 Knowledge Assessment." (See paper here.)
Allison had a careful development process for the FCS1 which she documented in a series of published papers and in her dissertation. There are some amazing nuggets buried in that work that really should be explored further. One of my favorites came out of her work developing the distractors for her test. On a typical test like this (e.g., think about any AP or GRE exam), there is a question (called a "stem" in the assessment literature) and a set of answers — one correct and 3-4 other "distractor" (i.e., wrong) answers. A good distractor is not just wrong — it’s a common wrong answer. That commonality helps to tease out the differences in understand between students.
To develop her distractors, Allison asked a sample of students who studied with different programming languages to answer the questions with just the stems — an open-ended question. Allison then collected the wrong answers and ranked them by how often they occurred. Here’s one of the tables from her dissertation showing the common wrong answers to one question, grouped by the programming language that students studied:
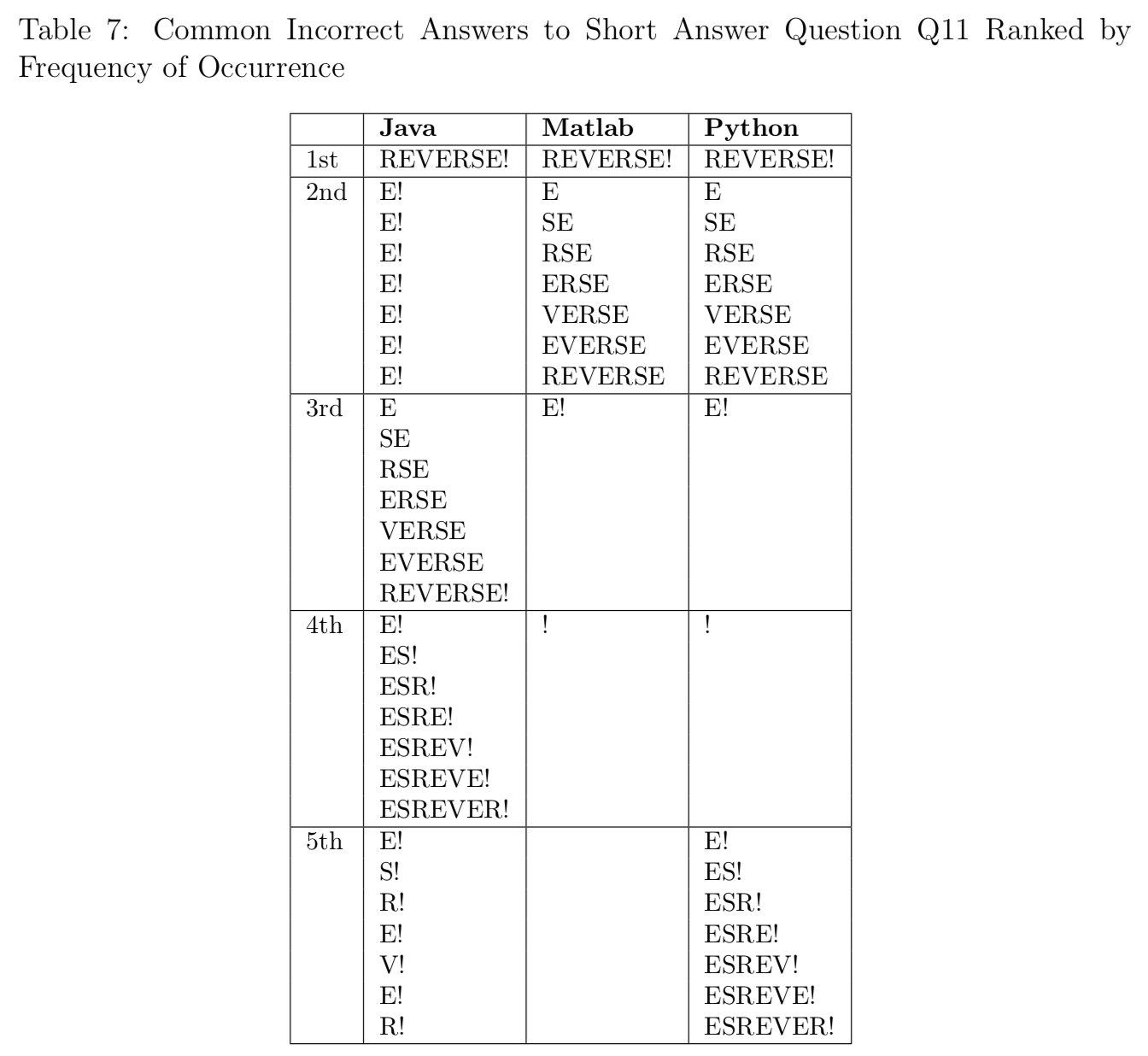
Notice that the most common wrong answer is exactly the same. The 2nd most common wrong answer in Java is idiosyncratic (which is interesting), but the 2nd most common wrong answer for both MATLAB and Python is the 3rd most common wrong answer for Java. The 4th most common wrong answer for Java is the same as the 5th most common wrong answer for Python. We didn’t see that wrong answer in MATLAB, but surprisingly, there were only 4 wrong answers for MATLAB.
It’s fascinating that there was such commonality across these different programming languages. It’s also interesting to consider why some wrong answers only appear in some languages, and if there are language features that limit the number of wrong answers that students might generate. But why is there such commonality? There are clear syntactic differences between these languages, but the semantics is actually pretty similar.
In the last few months, I’ve been reading more from the programming languages community, and I got to spend time at a Dagstuhl Seminar with experts in programming language semantics (which I talked about in this recent CACM blog post). Shriram Krishnamurthi convinced me that there is a theme of thinking in these papers that we really need to get away from. It’s simply wrong.
There is no language independence here. The FCS1 and SCS1 are multi-lingual which is a remarkable achievement. We might also call them pseudocode-based assessments, which is how they can be multi-lingual, but since a pseudocode-based test isn’t necessarily validated across other languages, "multi-lingual" is a stronger claim than "pseudocode-based." We do not cover all of any of those languages (Java, MATLAB, or Python), but we do cover the subset most often appearing in an introductory CS course.
They are clearly not language independent. In the great design space of programming languages, Java, MATLAB, and Python cluster together pretty closely. There are much more different programming languages than these — I’m sure it’ll take any reader here just a few moments to generate a half-dozen candidates whose learners would score poorly on the FCS1 and SCS1, from Scratch to Haskell to Prolog.
In my own research, I’m studying and developing task-specific programming languages (see blog post here) which may not even be Turing-complete. One cannot even ask the questions from FCS1 and SCS1 in these languages. If the assessment question cannot be asked, then clearly the question is dependent on certain language features.
There might one day be language-independent assessments in computing education research. The earliest reference I can find to the idea is Roy Pea’s 1986 paper "Language-independent conceptual ‘bugs’ in novice programming" (see paper here). The bugs he identifies are about the concept of programming (e.g., issues with parallelism, intentionality, and egocentrism). These don’t have to do with programming language features at all. These are issues that are early in the trajectories of learning programming (e.g., see here). That’s not the level of learning that we’re dealing with in FCS1 and SCS1.
We have different languages because we think that those differences make a difference. For an assessment to be language independent, it would have to be measuring something deeper than those differences. I don’t think we know enough about how to do that yet. We don’t yet know how to measure the cognition that is influenced by the differences between languages. The term "language independent" has stuck around for several years, which suggests that we as a research community haven’t thought deeply enough yet about the interaction between programming languages and cognition.
We argue that the FCS1 and SCS1 are "validated," and there is significant verbiage in our papers about what "validation" means. Validation is an argument that the assessment is valid because it measures something other than the test itself. Allison worked very hard to define exactly what she was measuring when she said "CS1 knowledge" because she learned that "CS1" means a lot of different things. We chose Java, MATLAB, and Python because those three languages are the most used languages in the majority of introductory computing courses. We can’t claim that we coverall of CS1 languages and it’s certainly not all of CS1 knowledge. FCS1 and SCS1 are valid in that they measure specific knowledge that is often in CS1 and that correlates to what teachers in those disciplines actually teach (e.g., as measured by textbook and syllabus coverage) and assess (e.g, as measured by their final exams). I’m proud of what Allison and Miranda accomplished, but they made their tests despite the vagaries of CS1. Where we made a mistake was that we addressed the majority of CS1’s (which teach Java, MATLAB, and Python) and used language that suggested that our assessment was valid for all languages that might be in CS1.
I like the strategy that David Weintrop and Uri Wilensky used in their assessment that was meant to explore the differences between blocks-based and text-based programming languages. They called their tool a "commutative assessment" (see paper here). That’s a nice idea. They’re not claiming independence or equivalency. Their tool is for exploring commutativity between these modalities. While the blocks and text languages that Weintrop and Wilensky studied were almost all just syntactically different (not semantically different), they did find differences in student errors and conceptions. Their results suggest that syntax and form of the language do make a difference, but it also suggests that we should expect even greater differences if we could compare semantic differences.
While I regret that it took me this long to realize that the phrase "language independent" was wrong, the fact that we did not build language independent assessments is exciting. The design space for programming languages is vast. The interaction between that design space and human cognition (especially our ability to learn the features in that design space) is mostly unexplored. I don’t know if we’ll ever understand enough to truly build a programming language independent assessment. It’s exciting to think about how much there is to learn before we could attempt to build one.
But here’s the bottomline take-away: We need to stop saying language-independent for these assessments. They’re really not. FCS1 and SCS1 are multi-lingual pseudocode-based assessments.
No entries found