Communications of the ACM
Data Anonymization Using the Random Sum Method

The urgency of the problem of personal data protection increases with the growth of global digitalization. This problem hinders the growth of many information technologies. Nowadays, information systems are used to process and store personal data in business, healthcare, and the public sector. The development of Big Data technologies and the increase in both computing power and the size of information storage have led to a rise in the volume of personal data collected around the world. The use of these technologies for building advertising strategies, sociological research, etc., is gaining popularity. At the same time, the risk of personal data leakage has increased many times over. However, for marketing and social research, it is not necessary to know the needs of a particular individual; only statistical information about a population of people is needed.
Personal data lead in the number and volume of leaks among restricted information. In fact, 11.06 billion records of personal data and payment information were compromised worldwide as a result of leaks that became public in 2020. Names and surnames, e-mail addresses, phone numbers, passwords, permanent residence information, social security numbers, bank card details, and bank account information became available. Although the absolute number of leaks in 2020 decreased by 5% as compared to that in 2019, the share of intentional cases increased to 72%. The way out of this situation is the anonymization of data containing personal information.
Anonymization (depersonalization) of personal data involves actions that irreversibly change personal data in such a way that a person can no longer be identified even with the use of additional information.1 The purpose of this blog post is to present an anonymization method that can be applied to the digital attributes of personal data. The purpose of its creation was to find a way to protect personal data without a significant loss of their useful qualities. This method is called the "Random Sum Method." It describes a way to convert personal data without a significant distortion of their statistical properties and is currently widely used in academic research.
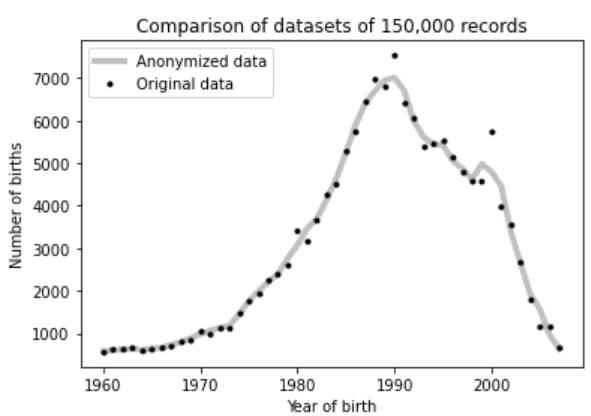
Let's illustrate this method using the example of the year of birth. In order to change the data, but keep all of their statistical properties, we need to add to this digital attribute a number randomly generated from the set (−1, +1, 0). Here, −1 decreases the value, for example, the year of birth becomes 1971 instead of 1972; 0 leaves the value unchanged; and +1 increases it by 1, i.e., 2006 is replaced with 2007.
The proposed method needs to check the quality of data depersonalization and reliability to assess the possibility of restoring the original dataset. Let's start by checking how different the original dataset is from its anonymized version. That is, we will evaluate whether there are statistically significant differences between these sets. To test the statement about the conservation of the statistical properties of the initial numerical data, the technique of generalization t-proximity was used.
To evaluate the effectiveness of this anonymization method, several experiments were carried out. The software implementation of this method was carried out in the Python 3 programming language. This language was chosen because of its ease of use, high speed of calculation, and clarity of graphical reports. The random library was used to implement the random selection function, the numpy and math libraries were used to calculate statistical indicators and mathematical functions, and the matplotlib.pyplot library was used to plot and conveniently display graphs.
The source of personal data needed for the experiments was the Russian social network VK.com. This social network was chosen because of the large amount of open user data, as well as the convenience of an API designed specifically for collecting such data. A random sample of 150000 user records was made with the attributes "Last Name," "First Name," and "Year of Birth." The data were stored in a Mongo DB database.
Thereafter, the collected data were subjected to the depersonalization procedure by specially written software, as described above. The resulting datasets were compared using Pearson's criteria for matching interval data. This study would help to modify, if necessary, the proposed method.
As a result of the analysis of the results obtained, we concluded that the described method was suitable for anonymizing personal data attributes with numerical values. In the considered case, it was possible to achieve the desired degree of trust in all the cases.
The reliability of the presented method could be characterized by the probability of recovering the original dataset. Computational complexity was estimated by the number of options for the enumeration of all the values of the anonymized set. However, this remark was valid only if there were no algorithm to reduce the computational complexity.
In the case when the reduction algorithm was unknown, it was necessary to use the algorithm of enumeration of all the data. The computational complexity of such an enumeration for a set of birth years containing N records was 3N. However, to find out which of the 3N datasets would be true, additional checks would be required, the computational complexity of which could not be predicted.
Note that this post presents an idea that describes a way to anonymize personal data and its initial testing. Naturally, this hypothesis needs further study and verification. The presented method can be adjusted according to the results of testing. Particular attention should be paid to the anonymization of other digital attributes of personal data,2 such as geolocation or transport documents. We invite colleagues to cooperate and are ready to answer questions and participate in the discussion of anonymization technologies.
Footnotes
[1] Machanavajjhala, A., Kifer, D., Gehrke, J. and Venkitasubramaniam, M., 2007. l-diversity: Privacy beyond k-anonymity. ACM Transactions on Knowledge Discovery from Data (TKDD), 1(1), pp.3-es.
[2] OCTOPIZE - Mimethik Data, https://octopize-md.com/en/
Alina Alemaskina is a Computer Security graduate at HSE University and network security systems engineer at Rostelecom Solar, Moscow, Russia. Andrei Sukhov is a senior member of ACM and a professor of HSE University. He may be reached at [email protected].
No entries found