Communications of the ACM
Mitigating the Base-Rate Neglect Cognitive Bias in Data Science Education

In our blog on The Base Rate Neglect Cognitive Bias in Data Science (published on July 5, 2022), we introduced the base rate neglect cognitive bias and demonstrated its effect on data science learners' interpretations of the performance of machine learning classifiers.
Specifically, we presented the lion classification question:
A machine learning algorithm was trained to detect photos of lions. The algorithm does not err when detecting photos of lions, but 5% of photos of other animals (in which a lion does not appear) are detected as a photo of a lion. The algorithm was executed on a dataset with a lion-photo rate of 1:1000. If a photo was detected as a lion, what is the probability that it is indeed a photo of a lion?
We explained the high percentages of learners who answered this question incorrectly (61%) by the base rate neglect cognitive bias. Based on Bayes' Theorem, we also calculated the answer to the medical diagnosis problem (Casscells et al., 1978), which is analogous to the lion classification question. This solution, however, requires the learner to understand conditional probabilities, an advanced topic that is quite complex and cannot be firmly grasped by all learners.
Two related pedagogical questions arise now: How can machine learning educators help learners cope with the base rate neglect cognitive bias? And, is it possible to bypass the use of Bayes' Theorem to solve such questions? In this blog, we attempt to answer these questions based on pedagogical knowledge borrowed from the field of cognitive psychology.
Similarly high percentages of erroneous answers were also observed by Casscells et al. (1978), who found that only 18% of participants in their study solved the medical diagnosis problem correctly (see our July 5, 2022 blog). In a follow up to that experiment, Cosmides and Tooby (1996) found that when the same problem was formulated using frequencies, the percent of participants who answered correctly increased to 56%. Here is their formulation of the medical diagnosis problem using frequencies:
One out of every 1,000 Americans has disease X. A test has been developed to detect when a person has disease X. Every time the test is given to a person who has the disease, the test comes out positive (i.e., the "true positive" rate is 100%). But sometimes the test also comes out positive when it is given to a person who is completely healthy. Specifically, 50 out of every 1,000 people who are perfectly healthy test positive for the disease (i.e., the "false positive" rate is 5%). Imagine that we have assembled a random sample of 1,000 Americans. They were selected by lottery. Those who conducted the lottery had no information about the health status of any of these people. Given the information above, on average, how many people who test positive for the disease will actually have the disease? _________out of___________".
To check whether Cosmides and Tooby's finding (56%) is exhibited also in the context of machine learning, we phrased a new question that deals with frequencies (natural numbers)—the tomato disease classification question—which is analogous to both the lion classification question and the medical diagnosis problem. It goes as follows:
A machine learning algorithm was trained to detect a leaf disease in photos of tomato bushes. The algorithm detects the diseased bushes perfectly, but 5 out of 100 healthy bushes are also detected as diseased. The disease affects about 1 out of 1,000 bushes. If a bush is detected as diseased, what is the probability that it is really diseased?
In the second phase of the research presented in the July 5, 2022 blog, we posed both the lion classification question with probabilities and the tomato disease classification question with frequencies to 153 data science learners. The results are presented in the figure below, in which green represents correct answers and red represents all types of wrong answers (the breakdown of wrong answers is irrelevant to the discussion here, and so it is ignored):
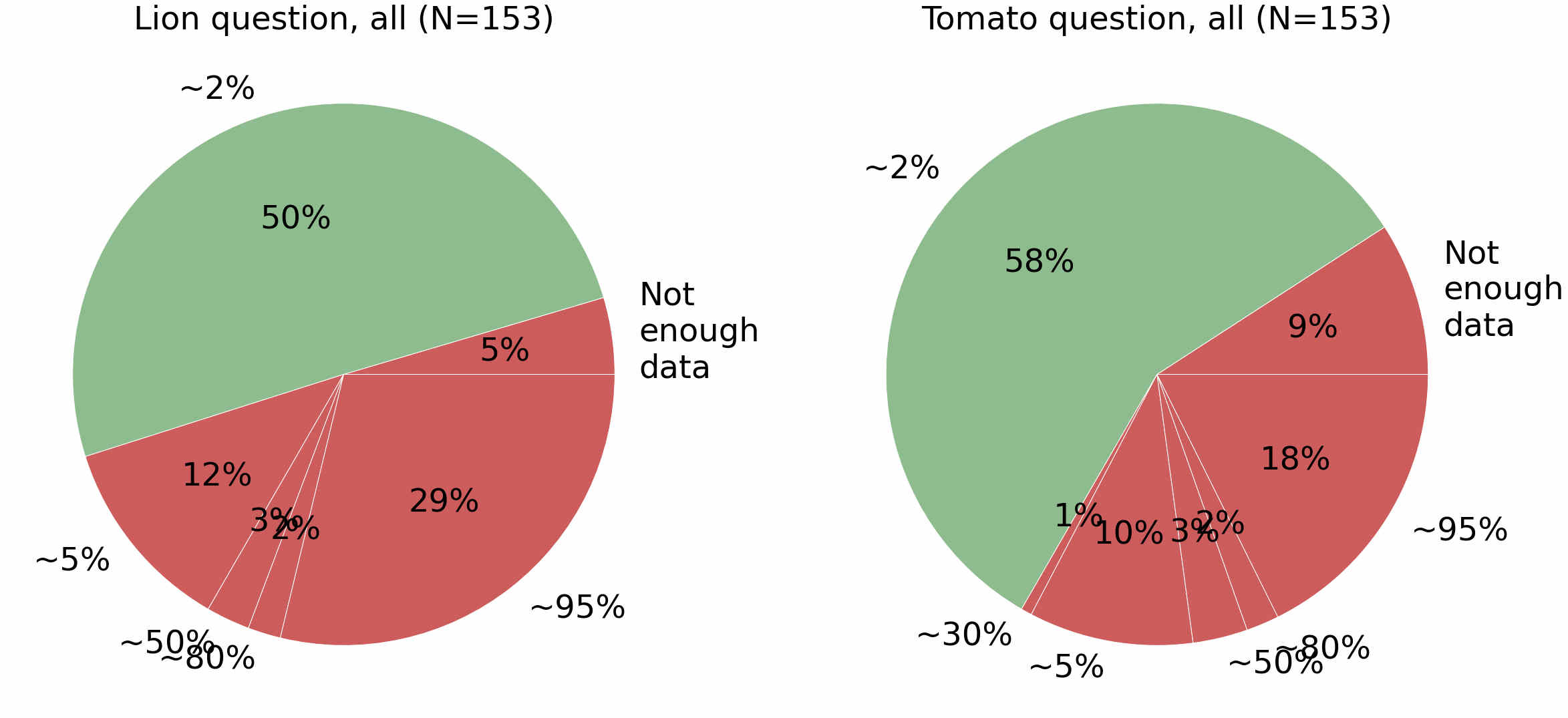
We can see that 58% of the data science learners answered the tomato disease classification question correctly, a result that is very similar to Cosmides and Tooby's result, whereby 56% respondents answered their frequencies version of the medical diagnosis problem correctly.
Furthermore, we can also see that the participants in the second phase, who were given both the frequencies and the probabilities formulations (which are, of course, analogous) in two different contexts (lion photos and tomato disease), exhibited a higher rate of success answering the lion classification question (probabilities; 50%) compared with participants who correctly answered the first phase questionnaire which presented only the probabilities formulation (39%). AA That is, the question that was phrased with frequencies (natural numbers, the tomato disease classification question in our case) bridged the learners' intuitive and analytical thinking and helped them arrive at a correct analytical solution for the formulation with probabilities (the lion photos classification question in our case).
So, how can the two pedagogical questions presented at the beginning of this blog be answered? Specifically, how can machine learning educators help learners cope with the base rate neglect cognitive bias? And, is it possible to bypass the use of Bayes' Theorem when solving such questions? Based on our teaching experience, we suggest a) formulating such questions using frequencies (i.e., natural numbers), and b) calculating the answers to such problems using a confusion matrix.
A confusion matrix is a representation of the correct and erroneous results of a classifier in the form of a matrix, whose rows represent the real labels and whose columns represent the predicted labels. The numbers on the diagonal of the confusion matrix represent the numbers of the correctly classified objects, and numbers that are not on the diagonal represent the number of incorrectly classified objects, when the predicted label differs from the true label.
The following table represents the confusion matrix of the lion classification question for a database with 1,001 images. According to the conditions presented in the question, one of those images contains a lion and the other 1,000 do not. Using this representation of the lion classification question, it is easy to compute its solution, that is, 1/(50+1) = ~2%.

As can be seen, by using frequencies (natural numbers) instead of probabilities (percentages), solving the lion classification question (and analogous questions) using a confusion matrix both mitigates the base rate neglect cognitive bias and bypasses the need to use Bayes' Theorem.
To conclude, we highlighted three tools that can mitigate the base rate neglect cognitive bias in the context of data science education:
- Introducing students to questions that are formulated with frequencies before introducing the same questions formulated with probabilities;
- Teaching students about confusion matrixes;
- As a pre-lesson activity in preparation for the lesson on performance measurement of machine learning algorithms, ask students to answer questions with both formulations (e.g., the lion classification question with probabilities and the tomato disease classification question with frequencies). Based on our teaching experience, this pre-lesson activity will reflect to the students their own biases and may promote their understanding of the importance and crucial role of the careful considerations required when implementing machine learning algorithms in real-world situations in the application domain.
References
Casscells, W., Schoenberger, A., and Graboys, T. B. (1978). Interpretation by physicians of clinical laboratory results. New England Journal of Medicine, 299(18), 999–1001. https://doi.org/10.1056/NEJM197811022991808
Cosmides, L. and Tooby, J. (1996). Are humans good intuitive statisticians after all? Rethinking some conclusions from the literature on judgment under uncertainty. Cognition, 58(1), 1–73.
Ejersbo, L. R. and Leron, U. (2014). Revisiting the medical diagnosis problem: Reconciling intuitive and analytical thinking. In Probabilistic Thinking (pp. 215–237). Springer.
Koby Mike is a Ph.D. student at the Technion's Department of Education in Science and Technology under the supervision of Orit Hazzan. Mike's research focuses on data science education. Orit Hazzan is a professor at the Technion's Department of Education in Science and Technology. Her research focuses on computer science, software engineering and data science education. For additional details, see https://orithazzan.net.technion.ac.il/.
No entries found