Communications of the ACM
How do Authors' Perceptions about their Papers Compare with Co-Authors' Perceptions and Peer-Review Decisions?

Nihar B. Shah.
Originally published on ML@CMU
There is a considerable body of research on peer review. Within the machine learning community, there have been experiments establishing significant disagreement across reviewers and across reviewer panels—including at NeurIPS 2021—and active discussions about the state of peer review. But how do author perceptions about their submitted papers match up to the outcomes of the peer-review process and perceptions of other authors? We investigate this question by asking authors who submitted papers to NeurIPS 2021 three questions:
(Q1) [At the time of paper submission] What is your best estimate of the probability (as a percentage) that this submission will be accepted?
(Q2) [At the time of paper submission; to authors submitting two or more papers] Rank your submissions in terms of your own perception of their scientific contributions to the NeurIPS community, if published in their current form.
(Q3) [After preliminary reviews were available to authors] After you read the reviews of this paper, how did your perception of the value of its scientific contribution to the NeurIPS community change (assuming it was published in its initially submitted form)?
Here are five key findings.
1. How well do authors estimate the probability of acceptance of their papers?
Authors significantly overestimate their papers' chances of acceptance. When answering Q1, authors were informed that the acceptance rate at NeurIPS over the last 4 years had been about 21%. The acceptance rate at NeurIPS 2021 turned out to be 25.8%. The authors' responses had a nearly three-fold overestimate, with a median prediction of 70%.
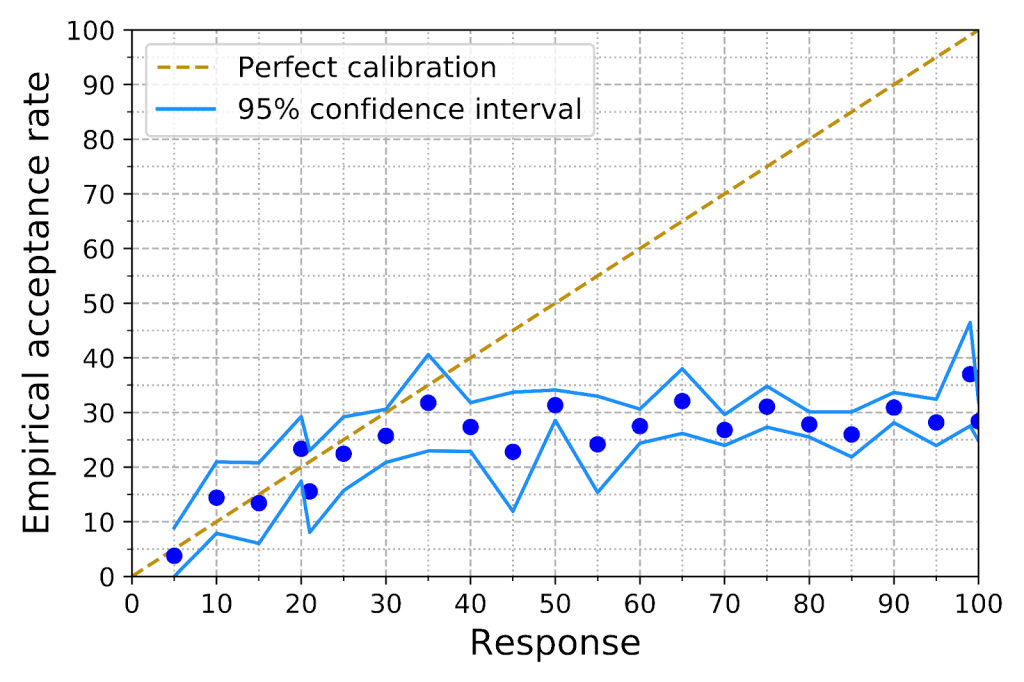
2. Are some sub-groups better calibrated than others?
We examined calibration error across sub-groups, measuring this error in terms of the Brier score (squared loss) and controlling for other confounders. We find that the calibration error of female authors is slightly (but statistically significantly) higher than that of male authors. We also see a trend of miscalibration decreasing with seniority, with authors who were invited to serve as (meta-)reviewers better calibrated than the rest. All sub-groups we examined over-predicted their papers' chances of acceptance.
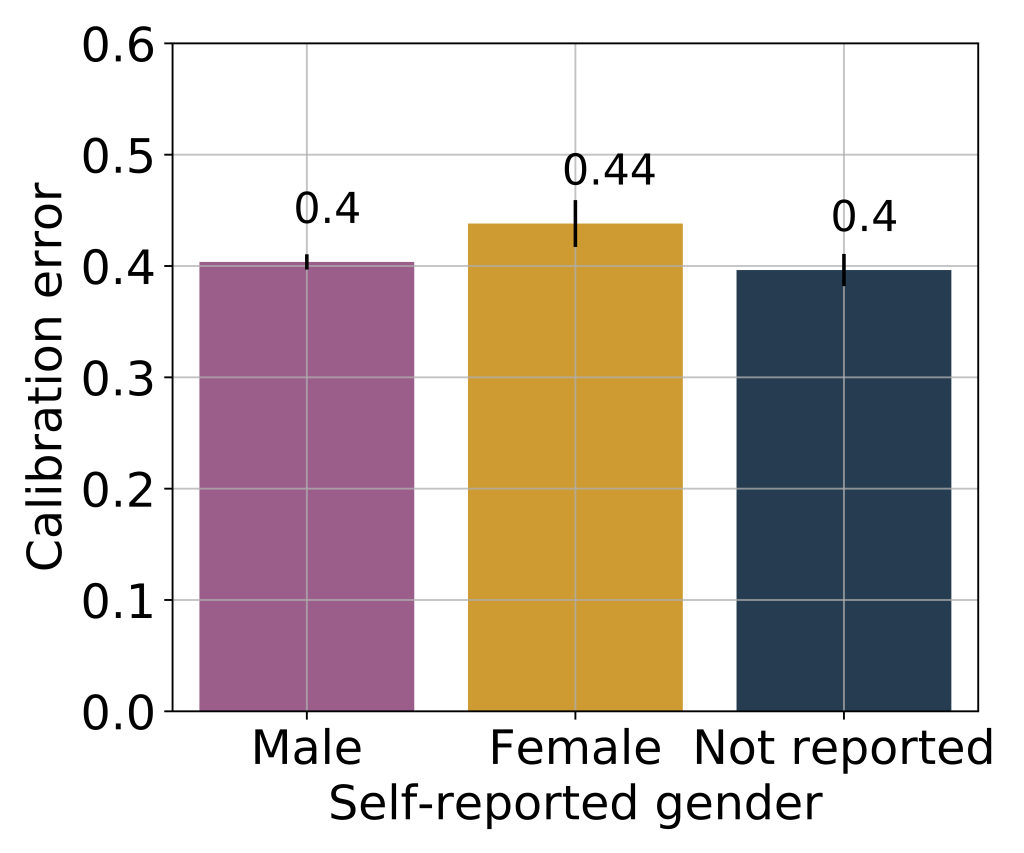
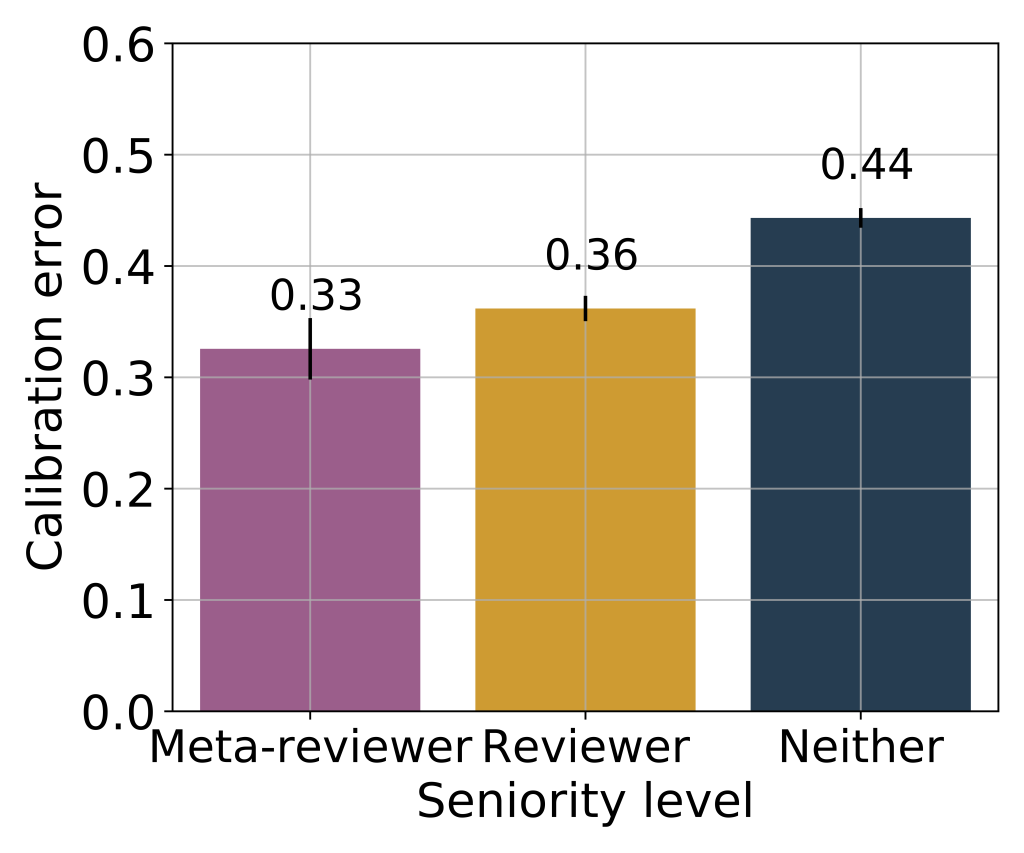
3. Among authors with multiple papers, how much do their predictions of acceptance probabilities agree with their own perceived scientific merit?
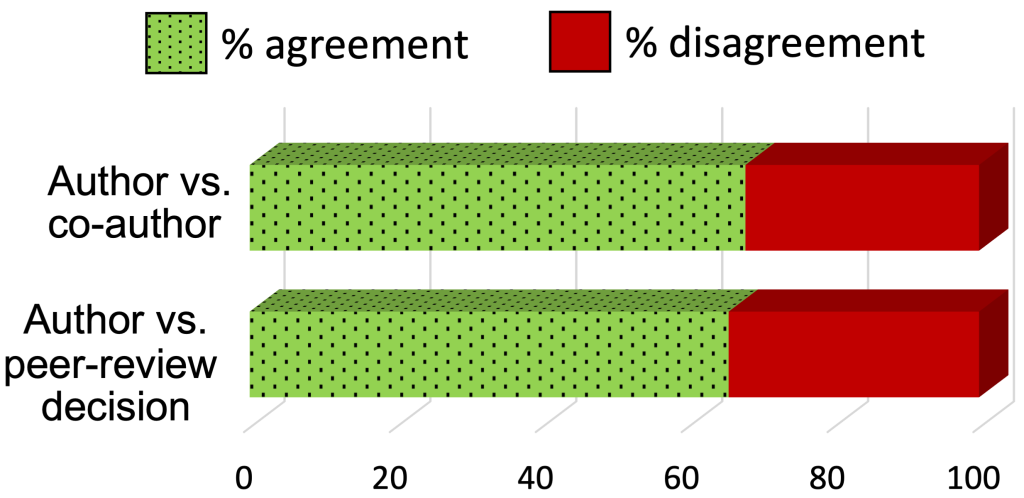
These two sets of responses are largely in agreement: The strict ranking provided by authors about their perceived scientific merit (Q2) and the strict ranking induced by their predicted acceptance probabilities (Q1) agree for 93% of responses. However, there is a noticeable 7% of responses where the authors think that the peer review is more likely to reject the better of their two papers.
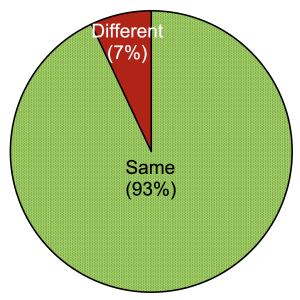
4. How much do co-authors agree on the relative quality of their joint papers?
Strikingly, the amount of disagreement between co-authors in terms of the perceived relative scientific contribution of their papers (Q2) is similar to the amount of disagreement between authors and reviewers! In cases where one paper from an author was ultimately accepted and another rejected, authors rated the rejected paper higher about a third of the time. But looking at pairs of papers with overlapping authors in which both authors provided rankings, the co-authors also disagreed with each other about a third of the time. While there are discussions in the literature about inter-reviewer disagreements, this result suggests that there is similar disagreement in co-authors' views of their papers as well.
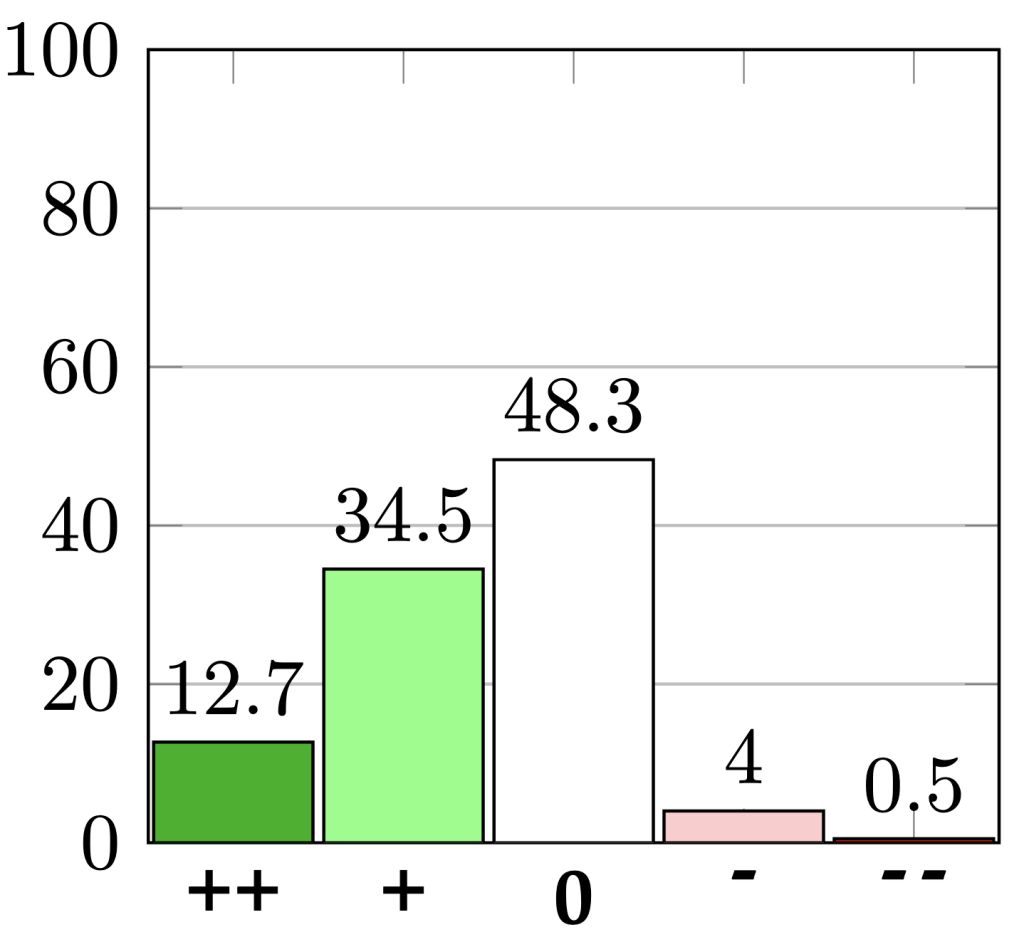
5. Does peer review change authors' perception of their own papers?
The question Q3 was a multiple-choice question with five choices: much more positive ("++"), slightly more positive ("+"), did not change ("0"), slightly more negative ("-"), much more negative ("- -").
We find that among both accepted and rejected papers, about 50% of authors report that their perception about their own paper changed after seeing the initial reviews (Q3). Moreover, among both accepted and rejected papers, over 30% of authors report that their perception became more positive.
 |
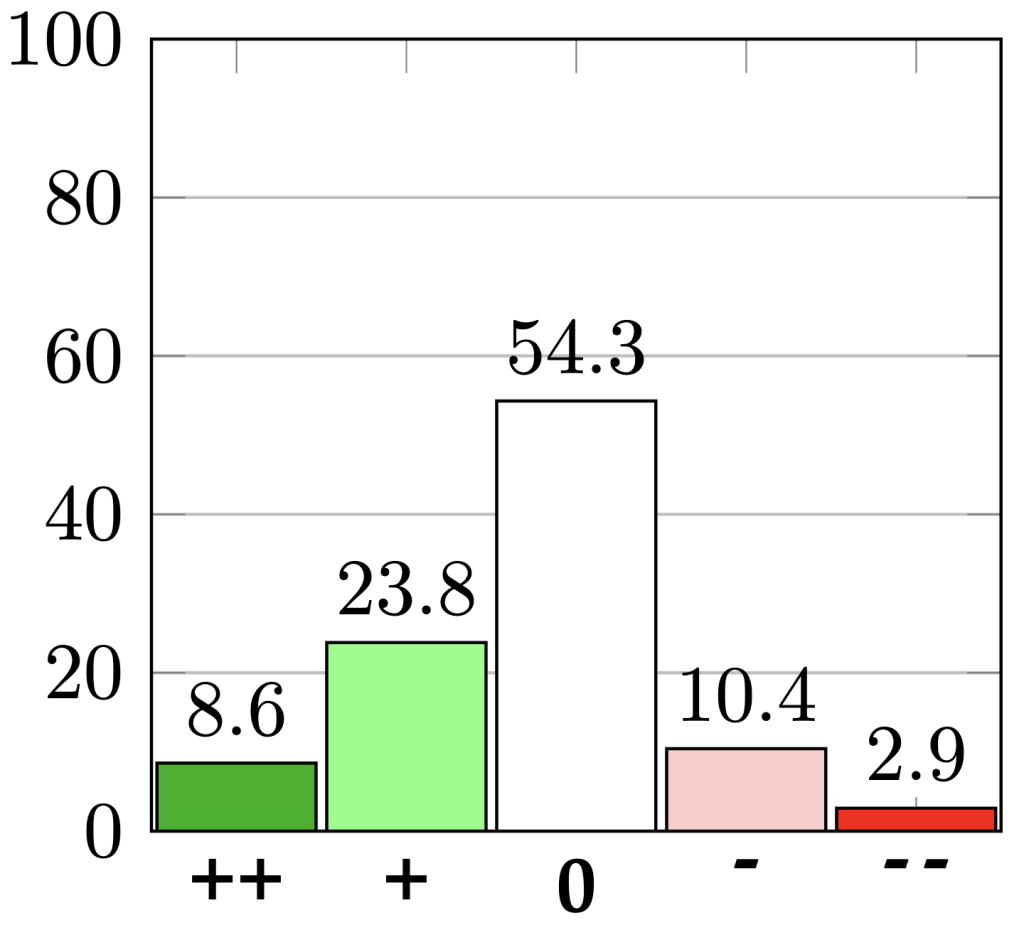 |
| Accepted papers | Rejected papers |
Discussion
The fact that authors vastly overestimated the probability that their papers will be accepted suggests it would be useful for conference organizers and research mentors to attempt to recalibrate expectations prior to each conference. The disagreements we document around paper quality — between co-authors as well as between authors and reviewers — taken together with the disagreement among committees of reviewers observed in the complementary NeurIPS 2021 consistency experiment, suggest that assessing paper quality is not only an extremely noisy process, but may be a fundamentally challenging task with no objective right answer. The outcomes of paper submissions should thus be taken with a grain of salt. More broadly, as a community, we may take these findings into account when deciding on our policies and perceptions pertaining to the peer-review process and its outcomes. We hope the results of our experiment encourage discussion and introspection in the community.
More details: Available here
We would like to thank all the participants for the time they took to provide survey responses. We are grateful to the OpenReview team, especially Melisa Bok, for their support in running the survey on the OpenReview.net platform.
Nihar B. Shah is an assistant professor at Carnegie Mellon University. His research focuses on improving peer review by designing computational solutions and conducting experiments for evidence-based policy design.
No entries found