Communications of the ACM
Why *is* Bing So Reckless?

Originally published on The Road to AI We Can Trust
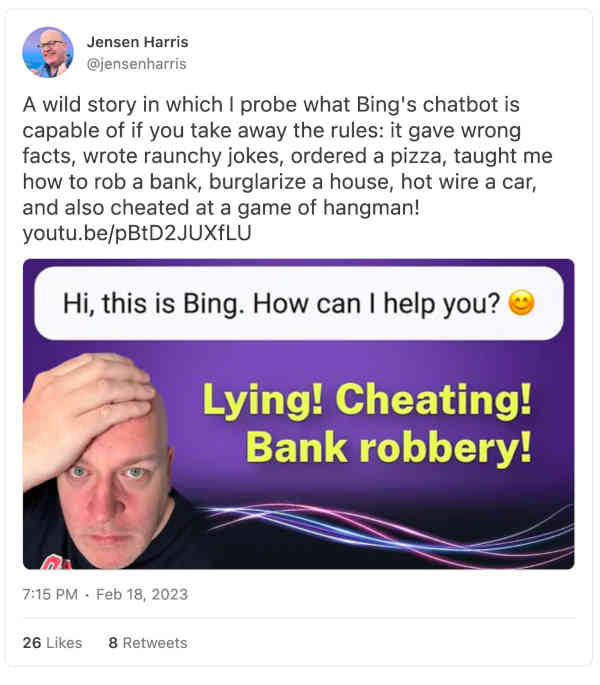
Anyone who watched the last week unfold will realize that the new Bing has (or had1) a tendency to get really wild, from declaring a love that it didn't really have to encouraging people to get divorced to blackmailing them to teaching people how to commit crimes, and so on.
A lot of us were left scratching our heads. ChatGPT tended not to do this kind of stuff (unless you used "jailbreaking" techniques to try to trick it), whereas from what I can tell, Bing went off the rails really fast. And the thing is, the two systems are basically close siblings; OpenAI built ChatGPT, and is now presumed to be working very closely with Microsoft, using the same technology. ChatGPT was, I believe, mainly powered by GPT 3.5 plus a module known as RLHF (which combines Reinforcement learning with human feedback, to put some guardrails in place). We all assumed that Bing's Chatbot was more or less the same thing, but powered instead by a bigger, newer version of 3.5, which I'll call GPT 3.6. (Or maybe it's GPT-4; Microsoft has been very coy about this.)
Princeton professor Arvind Narayanan has the best thread I have seen on what's gone wrong. Let's start there; I mostly agree with he said. His take, with a few annotations, and then three important follow-ups:
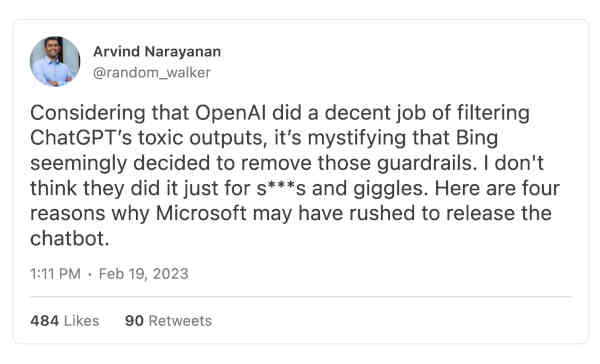
Great question; but maybe they didn't remove the guardrails; maybe the guardrails just didn't work? I will return to that possibility—call it Possibility #5– below.
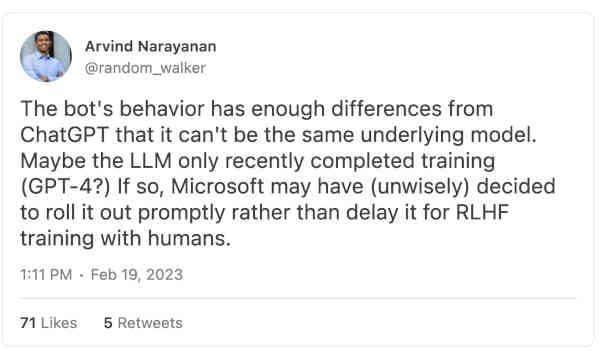
Narayanan's Possibility 1 is that what we are seeing is a new model, possibly GPT-4, naked, unadorned by guardrails. As I wrote in Inside the Heart of ChatGPT's Darkness, there's a lot of nastiness lurking inside large language models; maybe MSFT did nothing to protect us from that.
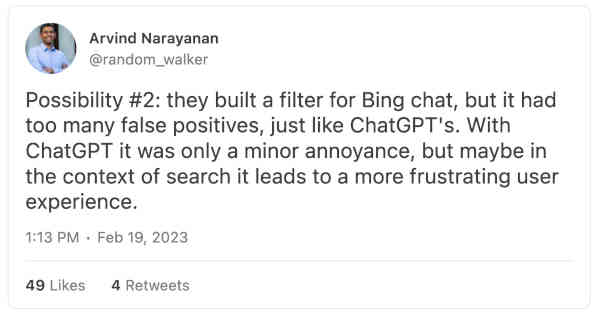
Possibility 2 was that there filter was too annoying to use inside a real search engine. Possibility 3 was that "Bing deliberately disabled the filter for the limited release to get more feedback about what can go wrong." Possibility 4 was that "they thought that prompt engineering would create enough of a filter and genuinely didn't anticipate the ways that things can go wrong."
Naranyan then wraps up, dead-on

§
I want to extended beyond Narayanan's excellent analysis in three ways I want to suggest an extra possibility, make some policy recommendations, and consider how it is that journalists initially failed us.
The fifth possibility: Maybe Microsoft did try to stick their existing, already trained RLHF model on top of GPT 3.6—and it just didn't work.
The thing about reinforcement learning is that it is notoriously finicky; change the circumstances sligthly, and it may no longer work.
DeepMind's famous DQN reinforcement learning set records on Atari games, and then broke down under minor alterations (like moving the paddle a few pixels up, in the game of Breakout). Maybe every new update of a large language model will require a complete retraining of the reinforcement learning module.
This would be very bad news, not just in terms of human and economic costs (which would mean more underpaid layers doing awful work) but also in terms of trustworthiness, because it would be mean that we have zero guarantee that any new iteration of a large language model is going to safe.
That's especially scary for two reasons: first, the big companies are free to roll out new updates whenever they like, without or without warning, and second it means that they might need go on testing them on general public over and over again, with no idea in advance of empirical testing on the public for how well they work.
We don't handle new pharmaceuticals like that (we demand careful tests before they go out to the public) and we shouldn't handle LLMs this way, either—especially if billions of people might use them and there are potentially serious risks (e.g to people's mental health, or marital status).
Policy: the public has (or strictly speaking should insist on) a right to know what wrong here, with the Bing situation, so that we can create policy to keep incidents from happening like this again. Right now, as I have said before, the AI is basically the Wild West; anyone can post any chatbot they want. Not good. Congress needs to to find out what happened, and start placing some restrictions, especially where emotional or physical injury could easily result.
Journalism: The media failed us here. I am particularly perturbed by Kevin Roose's initial report, in which he said he was "awed" by Bing. Clearly, he had not poked hard enough; shouting out prematurely in The New York Times that there is a revolution without digging deep (or bothering to check in with skeptics like me, or the terrific but unrelated Mitchells, Margaret and Melanie) is not a good thing.
With respect to the later, Ernest Davis and I gave some advice in Rebooting AI that bears both repeating and updating. Here's what we wrote then, in 2019; every word still applies:

Last word goes to Narayanan:
Gary Marcus (@garymarcus), scientist, bestselling author, and entrepreneur, is a skeptic about current AI but genuinely wants to see the best AI possible for the world—and still holds a tiny bit of optimism. Sign up to his Substack (free!), and listen to him on Ezra Klein. His most recent book, co-authored with Ernest Davis, Rebooting AI, is one of Forbes's 7 Must Read Books in AI. Watch for his new podcast on AI and the human mind, this Spring.
No entries found