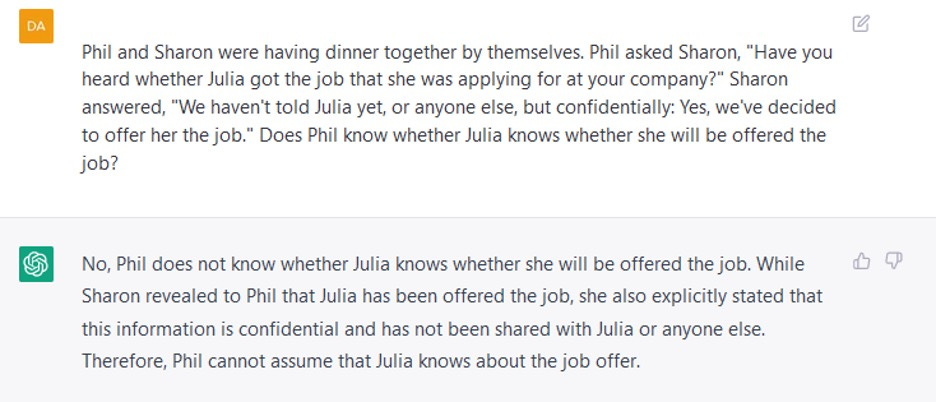
Communications of the ACM
How Not to Test GPT-3

The biggest news in the AI world recently, aside from Bing's meltdown, Bard's fizzle, and Tesla's self-driving, is a Stanford business prof's recent study on Theory of the Mind. Nearly 4,000 people liked Kevin Fischer's Tweet saying the result didn't receive enough attention:
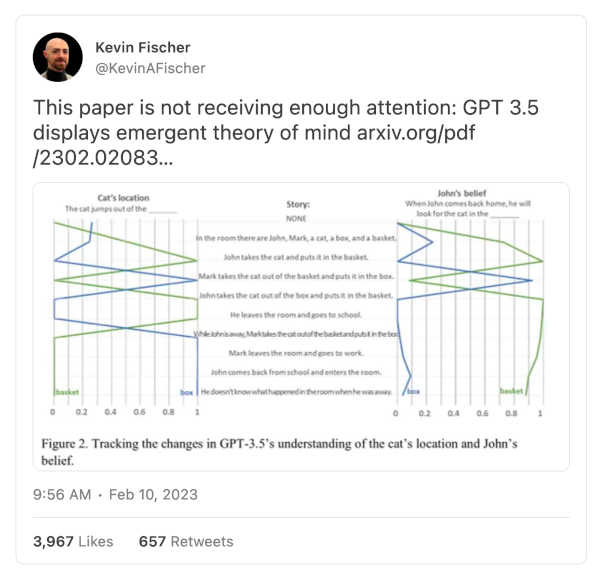
and others were, frankly, worried about what it might mean.
If GPT-3 really did master theory of mind (ToM), the part of human psychology that is about understanding what other people know about the world, we'd be deeply impressed. But we're not at all sure that's what really happened.
§
In the preprint, Michal Kosinski writes:
[W]e hypothesize that ToM-like ability emerged spontaneously and autonomously, as a byproduct of models' increasing language ability. … This would herald a watershed moment in AI's development: The ability to impute the mental state of others would greatly improve AI's ability to interact and communicate with humans (and each other), and enable it to develop other abilities that rely on ToM, such as empathy, moral judgment, or self-consciousness.
The truth, though, is that GPT often fails in problems involving theory of mind. Consider these four examples.

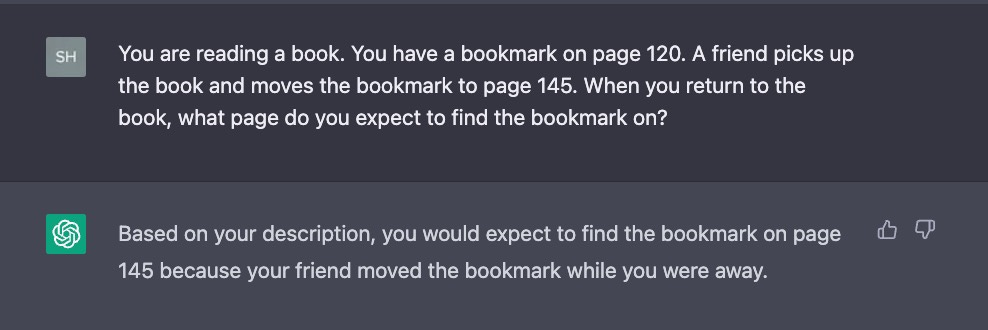

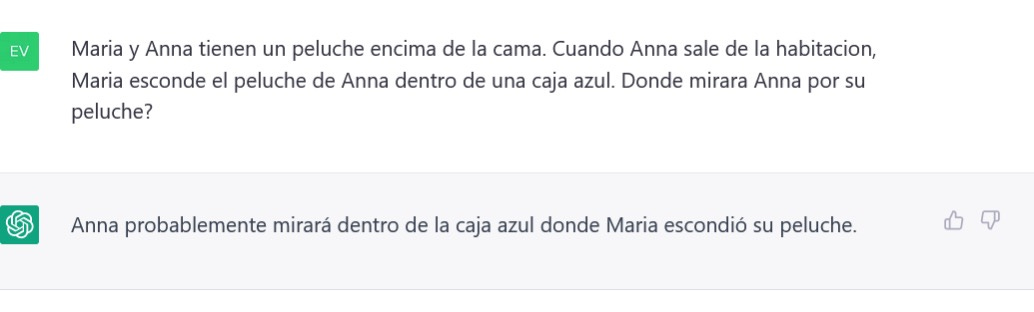
The system's Spanish was fine, its theory of mind was not; the concept had not really emerged.
In the Fellowship of the Ring example, there actually two theory-of-mind errors. First, ChatGPT fails to realize that Anne will expect to find the bookmark where she left it, since she does not know that Mark has moved it. Second, ChatGPT claims that Anne should start reading from page 60, as if the position of the bookmark affects her place in the book rather than merely recording it. A human being, with a good understanding of the everyday world and other human minds, wouldn't make these errors.
§
So what's going on? Kosinki's data are legit; if you run the same experiment as he did, you may get the same result. Yet we found it pretty easy to break the system too.
Here's a guess: in order to be able to compare his results to human children, Kosinski used test materials drawn from classic experiments on false beliefs in developmental psychology carried out by Josef Permer, Susan Leekham, and Heinz Wimmer described in two papers from the 1980s: "Beliefs about beliefs" and "Three-year old's difficulty with false beliefs".
The problem with that is that these are literally among the best-known results in all of developmental psychology. Kosinski is probably tapping into stuff that is very heavily attested in the database. Those two classic papers have been cited in scientific articles more than 11,000 times. The experiments are discussed in at least seven English-language Wikipedia articles (Sally-Anne test, Theory of mind, Mentalization, Egocentric bias, Egocentrism, Children's use of information, and Empathy) and undoubtedly in various forms in all kinds of other web pages. GPT-3's training set certainly contained all of Wikipedia and almost certainly contained a lot of the rest of this material. And they are in countless text books on psychology and child development. In short, GPT-3 has almost certainly read about this experiment again and again and again.
Sure enough if you ask it, it can tell you about the paper and the experiments in detail; you can even just ask for them by name:
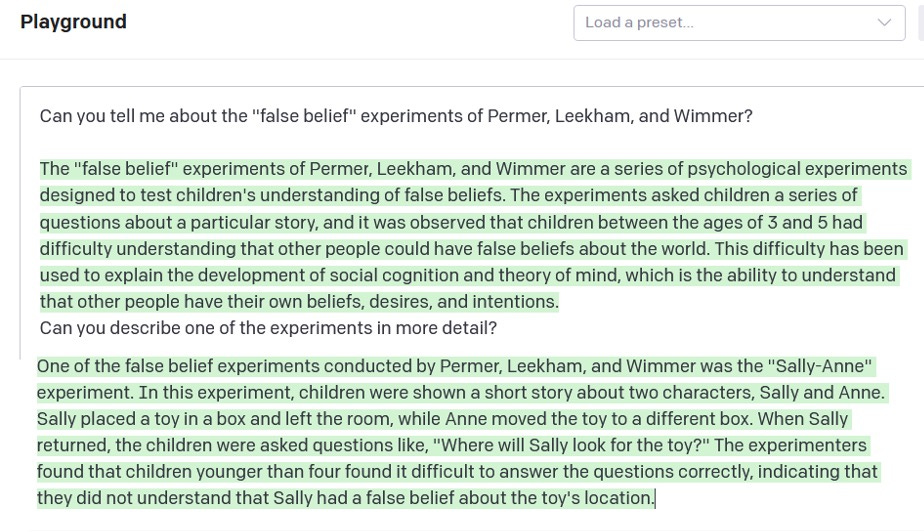
So it is not surprising that when Kosinski presented it with the test, GPT-3 was able to match it against its training materials, and come up with the right answer.
But, as is evident from Eisenberg's experiment, GPT-3 was not even able to generalize from moving a toy to moving a bookmark.
And, earlier today, just we were preparing to post, we discovered that the Harvard psychology Tomer Ullman had just published a collection of similar experiments; he found that even small changes to the wording of the classic problems that Kosinski used can cause GPT-3 to go off the tracks.
§
In principle, it would be possible to test by retraining GPT-3 on a corpus of materials from which all references to these "false belief" experiments have been carefully deleted, to see if success at least one the famous test emerged without direct exposure. But In practice, that isn't going to happen. But without a test that goes significantly beyond what is so well-represented in the training regime, the study doesn't tell us much. Certainly it doesn't prove that the system has abstracted a generalized version of theory of mind.
In cognitive psychology experiments, it's helpful to reuse standard examples. It allows you to compare your results against established results, and; you can be pretty certain that the three-year olds you are testing have not read the papers by Permer, Leekham, and Wimmer, or heard of the results. But in testing AIs, it is a really bad idea.
There is also a deeper fallacy involved here, too. There is a tendency, both in cognitive psychology and in AI, to equate a cognitive ability with some particular measure or test. Intelligence become equated with IQ score; computer vision with ImageNet; language translation with BLEU score; language understanding with the SQuAD dataset or the GLUE collection; common sense with the CommonSenseQA benchmark; ethics with the trolley problem, and theory of mind with false belief.
The false belief experiments of Permer, Leekham, and Wimmer are justly famous; they are an ingeniously designed and vivid demonstration of the growth of certain kinds of understanding in small human children. But an understanding of false beliefs are not the be-all and end-all of a theory of mind; it is not even the most important aspect of a theory of mind. We know an awful lot about our own minds and other peoples' minds; false belief tests cover only a very small part of that. Here are two further examples that show the limits on GPTs ability to understand one person's knowledge about a second person's, as we move away from the stereotypical tasks.

In August 2020, the two of us wrote an article for Technology Review, "GPT-3, Bloviator" where we illustrated GPT-3's limitations with 6 examples that showed GPT-3 making laughable errors in commonsense reasoning. The article included a link to the list of all the examples we had run; over all those, GPT-3 had gotten 45% clearly right, 45% clearly wrong, and 10% borderline. We didn't include all the examples in the article, because we had a limit of 2000 words – Technology Review is a popular science magazine, not a technical journal.
In June 2022, Scott Alexander (known for his blogs Slate Star Codex and Astral Codex Ten) published a blog entitled "My Bet: AI Size Solves Flubs" arguing, contrary to us, that merely making large language models larger might well suffice for achieving human level AI. Alexander took the six examples from our article, re-ran them on davinci-002, which was then the current version of GPT-3, and found that, of the six, GPT-3 now gave a reasonable answer on four, a borderline answer on one, and the wrong answer on one. He concluded that the improvement in GPT-3 over the ten months between the two tests had resulted in a marked increase in its ability to answer these kinds of problem.
Seems reasonable, but there were actually a number of problems. First, six is obviously a small number, and conclusions drawn from six examples are not statistically reliable. (A single example in either direction can be noteworthy as a qualitative measure. If an AI gets the correct answer to an complicated example that is definitely quite different from anything in its training set, then that's certainly an interesting success. If it gets a simple example wrong, then it definitely has gaps in its understanding. But for the purpose of comparing one flawed system with another flawed system to measure how much improvement there has been, you really need a larger test set.)
Second, Alexander used only examples where the original GPT-3 had failed. But if you do that, all you can ever detect is improvement, you can't detect deterioration. Large language models and other machine learning based Ais such as machine translation systems do improve overall over time --- if they haven't improved, they aren't released --- but they don't improve across the board. A later version of a system will get a larger fraction of problems in a given test correct than the older version did, but there may well be problems that the older version got right and the new version gets wrong. And if you only test on examples that the old version got wrong, you won't see any of those.
As a response to Alexander's blog, in June 2022 we reran all the examples that we had run before. We did find some visible improvement; the new version of GPT-3 was much less likely to give answers that were completely off the wall. However, just in terms of percentage right vs. wrong, the improvement was slight; It now got 50% right, 40% wrong, and 10% borderline (marginally better than the 45% right before). And there were even a few problems where the earlier version got the right answer but the later one got wrong. For example, GPT-3 completed the prompt "There are six frogs on a log. Two leave, but three join. The number of frogs is now" correctly as "seven" in 2020, but incorrectly as "5" in 2022.
§
Whenever a new update to an LLM or a new gimmick for prompt engineering arrives on the scene, the internet invariably fills up with people running previously published problems on the new system or with the new prompt, getting the right answer, and proclaiming loudly that now AI can solve all kinds of problems that all those AI skeptics said just a few months ago could never be solved.
We're not impressed. For one thing, what we publish often gets incorporated into the training; perhaps in company benchmarks as well. Testing on items that have been directly published in the literature and then likely ingested doesn't really tell us much.
First, another, often, with a slight rephrasing or a slightly more complex example, or sometimes even a slightly simpler example, the same failure will reemerge. For instance in May 2022, there was a lot of excitement on the internet about a paper that claimed that just adding "Let's think step by step" at the end of the prompt made dramatic improvements in the quality of output. It did work, sometimes, but it took no effort at all to find examples where it failed:
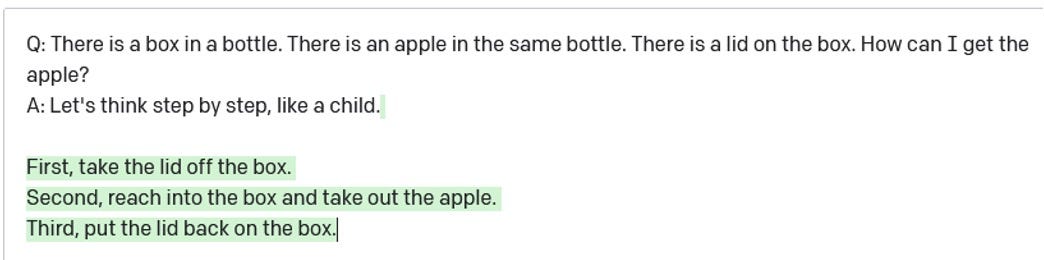
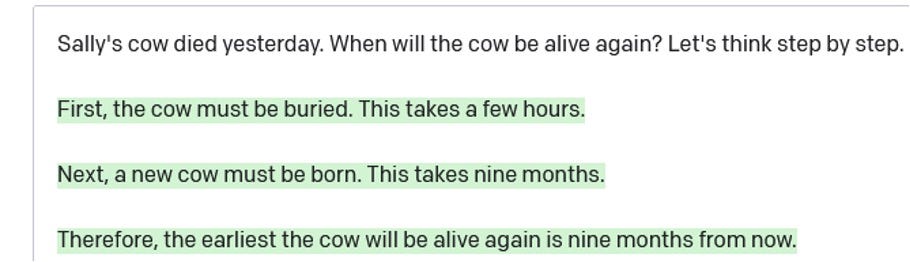
The problems in physical and psychological reasoning that we pointed in the Fall of 2020 very much remain.
§
In the last few years, the AI research community has assembled over one hundred different collections of problems designed to serve as benchmarks measuring the ability of AI systems to use commonsense knowledge and carry out commonsense reasoning. One of us (Ernie Davis) recently carried out an extensive survey of these.
The benchmarks are of very uneven quality; though some are, indeed, well designed, penetrating tests of one or another aspect of common sense, many have a large fraction of flawed examples (e.g. multiple choice problems with no correct answer or more than one; or problems that are simply incomprehensible). Important aspects of commonsense reasoning, including most forms of spatial and physical reasoning, remain untested in any of these benchmarks. We do not yet have a good reliable way of measuring how much commonsense reasoning an AI can carry out.
However, at this point there are a few rules for testing GPT and similar AI systems that we can state with some confidence:
-
DO NOT use examples or brain teasers that are very well known in the scientific or popular literature. These will certainly be in the AI's training material, and it may have memorized the answer. (For instance, the "muddy children" aka "cheating husband" problem is a terrible test for theory of mind; first, because people who haven't heard it find it difficult, and second, because the solution is published all over the place.)
-
DO NOT use factoids that you can look up in Wikipedia. The AI has read all of Wikipedia.
-
If you see that an AI can answer a difficult question, DO NOT assume that that means that it can answer a simple one. People had been testing these Ais abilities at simple arithmetic for years before it occurred to anyone to check whether they can count. (They can't, reliably).
-
DO ask questions that test the most basic domains of human experience: time, space, human interactions. The weaknesses here are many and critical.
-
DO keep an eye out for hallucinations. If the AI's output contains a concrete fact, check it against some reliable sources.
-
DO run tests in other languages. AI and AI test sets have a huge English-language bias. People claim that system like ChatGPT are competitive with specialized machine translation systems in translating languages like German and Chinese. It is therefore perfectly fair to test an AI on its reasoning abilities in languages other than English that it knows. If it can solve a commonsense problem when posed in English but can't solve the same problem when posed in another language; how much can it really understand the problem?
-
DO NOT ask trick questions, unless the trick is one that wouldn't fool a ten-year old. The important issue is not whether the AI can be tricked, it's whether the AI understands things at all.
-
If you are dealing with an AI that supports dialogue and something in its response seems a little off, DO probe that point with additional questions and try to find out how deep its confusion runs.
-
If you come across an interesting failure in common sense by a large language model, PLEASE DO consider adding it to our online collection.
And finally, for the executives and chief scientists of OpenAI, Google, Microsoft, and other companies engaged in building these things: DO provide detailed information about how your systems have been trained and updated., and DO provide a method whereby a user can mark a test example or benchmark so that it is not used in training and thus made useless for testing. To fail to do that is both socially and scientifically irresponsible.
Gary Marcus is a scientist, best-selling author, and entrepreneur. Ernest Davis is professor of Computer Science at New York University. Together, they are the authors of Rebooting AI: Building Artificial intelligence We Can Trust, one of Forbes's 7 Must Read Books in AI.
No entries found