Communications of the ACM
Can LLMs Really Reason and Plan?

Large Language Models (LLM's) are saturating the waves of AI discourse, and arguably rightly so. After all, their seeming approximate omniscience, and near-pitch-perfect form are things none of us has foreseen. Generative AI in general, and large language models in particular, are amazing idea generators. Over the weekend, Wall Street Journal reported a study that pit GPT4 against a bunch of MBAs in generating "innovative ideas" and the MBA's were apparently not even close! This seeming proficiency of LLMs to generate ideas in compelling form has led many to view them as essentially "AI-complete," and to ascribe to them reasoning and planning abilities.
Nothing in the training and use of LLMs would seem to suggest remotely that they can do any type of principled reasoning (which, as we know, often involves computationally hard inference/search). While one can dismiss the claims by hype-fueled social media influencers, startup-founders and VC's, it is hard to ignore when there are also peer-reviewed papers in top conferences making similar claims. The "Large Language Models are Zero-Shot <insert-your-reasoning-task>" is almost becoming a meme paper title! At some level, this trend is understandable as in the era of LLMs, AI has become a form of ersatz natural science–driven by observational studies of capabilities of these behemoth systems.
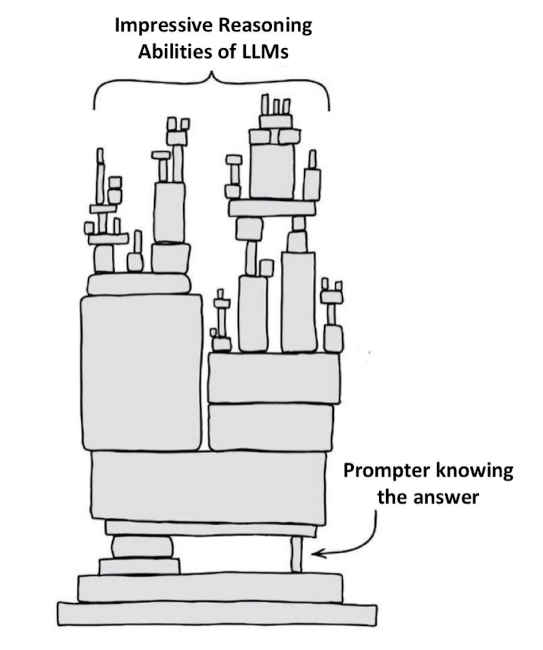
So, are these n-gram models on steroids really capable of planning and reasoning? In the summer of 2022, when we wanted to better answer this question, most reasoning claims were still somewhat anecdotal. So, we set out to evaluate GPT3 on a set of planning instances derived from the domains typically used in the International Planning Competition (IPC)–including the well-known Blocks World. Our results were quite contrary to the anecdotal claims about the planning abilities of LLMs, and when we made them public, received some attention in the AI circles..
By the beginning of this year, with the wide-spread public release of ChatGPT, and later, GPT4, there were a slew of additional claims, including in refereed papers, about LLM's abilities to reason and plan. So we decided to repeat our tests on both GPT3.5 and GPT4. Initial results showed that there was some improvement in the accuracy of generated plans from GPT3 to GPT3.5 to GPT4, with GPT4 reaching 30% empirical accuracy in the Blocks World (albeit still lower in other domains). We then wanted to know whether the modest improvement is because of the improved approximate retrieval abilities or whether GPT4 is actually doing/searching for plans.
Let us pause to note that our interest here is not whether LLMs can fake reasoning (by giving correct answers to reasoning tasks from memory and pattern finding), but whether they can actually do reasoning. Of course, seeing patterns in reasoning problems is not anything to be sneezed at. After all, our interest in mastering it is what is behind much of "street fighting" math (e.g., Polya's "How to Solve it"). But finding approximate shortcuts over provably correct reasoning procedures is obviously not equivalent to doing reasoning--unless you have an ability to establish from first principles reasoning that your hunch is actually correct. It is challenging to decide whether a system (or a human, for that matter) is memorizing or solving a problem from scratch–especially as the systems (or humans) get trained on larger and larger "question banks." This is a challenge that most instructors and interviewers are acutely aware of. Think of that infamous "why are manhole covers round?" interview question. While it may well have given the interviewer an insight into the candidate's analytical reasoning skills the very first time it was asked, all it does with high probability now is to confirm whether the candidate "trained on the interview question banks."
Considering that the LLMs don't suffer some of the normal limitations of humans–such as having a life on the side, and thus not having the inclination to focus exclusively on the test/interview preparation for long periods, we wanted to check if the improved performance of GPT4 is really coming from its ability to plan. One way of doing this for planning tasks is to reduce the effectiveness of approximate retrieval by obfuscating the names of the actions and objects in the planning problem. When we did this for our test domains, GPT4's empirical performance plummeted precipitously, despite the fact that none of the standard off-the-shelf AI planners have any trouble with such obfuscation. As these results came about at the height of sparks of AGI/existential risk angst, we couldn't resist the tongue-in-cheek editorializing that if GPT4 ever goes rogue, you can stymie it by throwing it a simple planning problem! Humor aside, nothing in our studies showed that GPT4 is capable of generating executable plans autonomously.
Perhaps they can't do planning autonomously straight out of the box, but what if we help them a little? There are broadly two popular techniques for such nudging. First, called "fine tuning" is rather straightforward–you take a general LLM and fine tune it on planning problems (i.e., instances and their solutions), with the hope that they will subsequently show better performance. While our own limited experiments didn't show any significant improvement through fine tuning, it is possible that with even more fine tuning data and effort, the empirical performance may well improve. But all that such fine tuning is doing is converting the planning task into a memory-based (approximate) retrieval. It doesn't prove that LLMs are able to plan.
The second way to improve the planning (and reasoning) performance is to prompt the LLM with hints/suggestions about how it can improve its initial plan guess. The crucial questions here are (a) whether this back prompting is manual or automated (b) who is certifying the correctness of the final answer and (c) whether the prompts inject additional problem knowledge or are just merely exhorting the LLM to try again "thinking more carefully" as it were.
The cleanest approach–one which we tried in our own work–is to let an external model-based plan verifier do the back prompting and certify the correctness of the final solution. In contrast, by far the more popular methodology is to have the human in the loop prompt the LLM–the so-called "chain of thought prompting (CoT)." The problem with CoT is that it is highly susceptible to the Clever Hans effect, where the LLM is merely generating guesses, and it is the human in the loop, with the knowledge of right vs. wrong solutions, who is steering the LLM–even if they didn't set out to do so deliberately. The credit and blame for the ensuring accuracy, if any, belongs squarely to the human in the loop. The relevance of such a framework becomes questionable when the human-in-the-loop doesn't know (or is unable to verify) the answer to the reasoning/planning problem themselves (and hence my tongue-in-cheek proposal for the forest of jumbled thoughts prompting).
A variation on the second approach is to have the LLM itself "critique" the guesses it generates and iteratively self-improve. Although some papers seem to swear by such a "self-improvement" capability in LLMs, the plausibility of such a claim hinges on the belief that the LLMs are better at verifying their solutions than they are at generating them. While never explicitly justified, the assumption rests on either analogies to humans or indirect nods to computational complexity arguments. Humans sometimes do show the capability of correcting their own erroneous guesses with self-critiquing–there seems to be no basis for that assumption in the case of LLMs. And while for many computational tasks (e.g. those in class NP), the verification is often of lower complexity than generation, that fact doesn't seem particularly relevant for LLMs which are generating (approximately retrieving) guesses, rather than actually solving the problem with guarantees.
While the foregoing questions the claims that LLMs are capable of planning/reasoning, it is not meant to imply that LLMs don't have any constructive roles to play in solving planning/reasoning tasks. In particular, their uncanny ability to generate ideas/potential candidate solutions–albeit with no guarantees about those guesses–can still be valuable in the so-called "LLM-Modulo" setups, in conjunction with either model-based planners, external solvers or expert humans in the loop. The trick is to recognize that LLMs are generating potential answers to be checked/refined by external solvers, and avoid ascribing autonomous reasoning capabilities to LLMs. Indeed, the LLM orchestration frameworks, such as the popular LangChain are best understood in this way.
The skeptical reader might now ask "but what about all those papers in high profile AI conferences that claim to show planning abilities of LLMs?" To analyze those claims, we need to first understand that solving planning tasks requires (a) having the necessary planning domain knowledge–the actions and their preconditions, effects; the standard hierarchical recipes (e.g. task reduction schemas in HTN planning), past cases/plans, etc., and (b) being able to assemble this planning knowledge into an executable plan that takes care of any subgoal/resource interactions. The first can be called the knowledge acquisition and the second reasoning/planning part. Many of the papers claiming planning abilities of LLMs, on closer examination, wind up confusing general planning knowledge extracted from the LLMs for executable plans. When all we are looking for are abstract plans, such as "wedding plans," with no intention of actually executing the said plans, it is easy to confuse them for complete executable plans. Indeed, our close examination of several works claiming planning capabilities for LLMs suggests that they either work in domains/tasks where subgoal interactions can be safely ignored, or delegate the interaction resolution (reasoning) to the humans in the loop (who, through repeated prompting, have to "correct" the plan). Sometimes, in common sense domains, or with enough fine tuning, the "assembling" part may also be obviated by having seen a case that pretty much corresponds to the problem that needs to be solved. Without these assumptions or mitigations, the plans that come out of LLMs may look reasonable to the lay user, and yet lead to execution time interactions and errors. (These issues are illustrated in part by a recent news story about the proliferation of travel planning books, mostly auto-extracted from LLMs, and the ensuing disappointment of the unsuspecting end users who buy them mistaking them for usable plans).
The fact that LLMs are often good at extracting planning knowledge can indeed be gainfully leveraged. As we have argued in our recent work, LLMs can thus be a rich source of approximate models of world/domain dynamics and user preferences,, as long as the humans (and any specialized critics) in the loop verify and refine those models, and give them over to model-based solvers. This way of using LLMs has the advantage that the humans need only be present when the dynamics/preference model is being teased out and refined, and the actual planning after that can be left to planning algorithms with correctness guarantees (modulo the input model). Such a framework has striking similarities to knowledge-based AI systems of yore, with LLMs effectively replacing the "knowledge engineer." Given the rather quixotic and dogmatic shift of AI away from approaches that accept domain knowledge from human experts, something I bemoaned in Polanyi's Revenge, this new trend of using LLMs as knowledge sources can be viewed as a form of avenging Polanyi's revenge! Indeed, LLMs make it easy to get problem-specific knowledge as long as we are willing to relax correctness requirements of that knowledge. In contrast to the old knowledge engineering approaches, LLMs offer this without making it look like we are inconveniencing any specific human (we are, instead, just leveraging everything humans told each other!). So the million dollar question for reasoning tasks is: "how would you do planning if you have some doddering know-it-all ready to give you any kind of knowledge?" Traditional approaches to model-based reasoning/planning that focus on the incompleteness and incorrectness of the said models (such as model-lite planning, robust planning) can have fresh relevance.
To summarize, nothing that I have read, verified or done gives me any compelling reason to believe that LLMs do reasoning/planning as it is normally understood. What they do, armed with their web-scale training, is a form of universal approximate retrieval which, as we have argued, can sometimes be mistaken for reasoning capabilities. LLMs do excel in idea generation for any task–including those involving reasoning, and as I pointed out, this can be effectively leveraged to support reasoning/planning. In other words, LLMs already have enough amazing approximate retrieval abilities that we can gainfully leverage, that we don't need to ascribe fake reasoning/planning capabilities to them.
Additional resources:
A recent 30-minute talk that argues these positions can be found at this link.
A recent tutorial I gave at the Intl. Conference on Planning & Scheduling, on the role of LLMs in Planning, provides a more comprehensive survey and analysis.
The papers https://arxiv.org/abs/2305.15771 , https://arxiv.org/abs/2206.10498, and https://arxiv.org/abs/2305.14909 describe the details of our own work referred to in the article.
Subbarao Kambhampati is a professor at the School of Computing & AI at Arizona State University, and a former president of the Association for the Advancement of Artificial Intelligence. He studies fundamental problems in planning and decision making, motivated in particular by the challenges of human-aware AI systems. He can be followed on Twitter @rao2z.
Comments
Hua Wei
Really insightful reasoning steps to verify LLMs ability to reason and plan! Now it's LLMs' turn to reason on the proposed reasoning steps!
Vadims Casecnikovs
Would love to know what are the best practices to incorporate LLM as part of reasoning framework.
Do I understand correctly, that the easiest metric right now for AGI are problems like Block World
Displaying all 2 comments