Communications of the ACM
Let's Be Objective about Large Language Models


Credit: Walid S. Saba
Created using Generative AI Tools
1. Large Language Models: The End of History?
Since the advent of the transformer and attention mechanisms [1] large language models (LLMs) have been all the rage, not only in the artificial intelligence (AI) community but in all of science and technology and even in business and society at large (the query "Large Language Models" I recently executed on Google returned over 2 billion hits). Recently, some AI luminaries (e.g., [2]) have even stated that several years from now we will look back at LLMs as the point when we had the first sparks of artificial general intelligence (AGI).
Undoubtedly, the exuberance surrounding LLMs is due in part to their impressive and admittedly human-like linguistic fluency. But linguistic fluency is quite different from linguistic competency. LLMs, that are essentially a massive experiment in a bottom-up reverse engineering of language at scale, have indeed reached a point where they have captured (‘learn’) the syntax and quite a bit of the semantics of natural language. This has allowed these massive networks to generate (via completion) very fluent and human-like language in response to any prompt. But how do we measure the linguistic competency of these LLMs?
2. Formal vs. Informal Languages
A language belongs to one of two categories: formal languages or informal languages. Formal languages can themselves be divided into various sub-categories, such as programming languages (e.g., Java, Python, LISP, etc.); specification languages (e.g., HTML, XML, RDF, PDF, PostScript, etc.); or notational languages (e.g., musical notation). Note that both formal and informal languages can be finite or infinite languages. Infinite languages are an infinite set of valid statements that are generated by a recursive grammar: the number of expressions we can make in English is infinite, and the number of valid Python programs that we can write is also infinite. One major difference between formal and informal languages is context. Formal languages, for example, are semantically closed languages in that interpreting an expression in a formal language does not require any additional (contextual) information from outside the content of the expression itself. Informal languages, on the other hand, are not closed systems since the meaning of any expression in these languages cannot be fully determined from the content of the expression alone. In natural language, for example, it is widely accepted that a full understanding (comprehension) of linguistic content requires access to additional information not explicitly stated in the text (we usually refer to that information by ‘background commonsense knowledge’). And this is why LLMs that are learned from a vast corpus (no matter how large) will never truly ‘understand’ language – true language understanding requires access to knowledge of the world that we talk about in language (we will see how this can be tested shortly).
In general, language interpretation (or language understanding, or language comprehension) is a function that goes from one language category to another, and thus we have four possible mappings, namely (i) going from a formal language to another formal language; (ii) going from a formal language to an informal language; (iii) going from an informal language to a formal language; and (iv) going from an informal language to another informal language. When we speak of ‘natural language understanding’ by machines we are implicitly referring to two of these four mappings, namely mapping from an informal language to a formal language and vice versa. In figure 1 below we show examples of these four combinations.
Let us now discuss these four mappings in some detail.
2.1 formal language => formal language
The easiest of these four mappings is mapping one formal language into another formal language (square 1 in figure 1). Translating one formal language to another, a problem that is referred to as ‘source-to-source translation’ is a problem that computer scientists conquered in the very early days of computer science. While it is an impressive technology, the problem is algorithmically well-defined since formal languages do not admit ambiguity nor do they require additional (contextual) information for their interpretation. Undoubtedly, most computer scientists have used this technology by converting, for example, JSON to XML, or Java to C++, etc. Here are two examples of translating an expression in structured languages like Java into an expression in LISP, and translating a Python function into a PROLOG predicate:
Java to LISP
expr1 op expr2
=>
(op expr1 expr2)
Python to PROLOG
def p(m, x):
if x == 0:
y = f(m)
else:
y = 0
=>
p(m, 0, y) :- x != 0
p(m, x, y) :- y = f(m)
Note that this type of mapping is completely objective – that is, we can always objectively decide on the correctness of the mapping since the original program and the translation program can always be tested on input-output pairs to make sure the semantics of the two programs are equivalent.
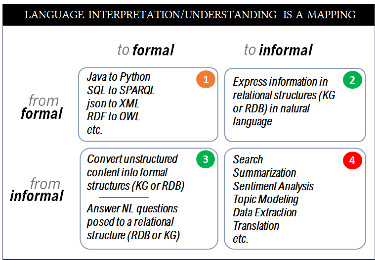
Figure 1. Interpretation is a mapping from one type of language into another.
Mappings from informal to informal languages are wholly subjective
and thus are not good benchmarks for the evaluation of linguistic competency.
2.2 informal language => informal language
Before we discuss squares (2) and (3) in figure 1, we will briefly discuss square (4), which is the translation (mapping) of an informal language to another informal language. The most obvious example of such mapping is machine translation, where the task is the translation of some natural (informal) language (e.g., English) to another natural (informal) language (e.g., French). But this mapping also involves tasks such as summarization, which is a mapping of some informal language (say English) to a summary of the text (which could be in the same informal language). Sentiment analysis is also a mapping from an informal language to an informal language namely the mapping of some text to a score that is supposed to measure the sentiment expressed in the text. What is unique about mapping from informal to informal languages is that evaluating their correctness is not objective, but is an entirely subjective process: my summary or yours, my search results or yours, my translation or yours? Unfortunately, and while the evaluation of these tasks are absolutely subjective, all current benchmarks that are used to evaluate LLMs are based on these tasks.
But if these subjective tasks are not appropriate benchmarks for the evaluation of the linguistic competency of LLMs, then what are the appropriate benchmarks?
2.3 Mapping between informal and formal languages
Examples of mappings between formal and informal languages (squares (2) and (3) in figure 1) can be objectively and decidedly tested. One such task would be ‘reading off’ the facts expressed in a relational structure (in some database or knowledge graph) in some natural language. The opposite process – this is a mapping from a formal to an informal language, which is square (2) in figure 1. The most important objective tasks that can test linguistic competency, however, are the examples shown in square (3) of figure 1, namely mapping from an informal language (e.g., English) to a formal language (e.g., SQL or SPARQL). This would involve tasks such as translating an English question into an ambiguous SQL query or translating free-form text expressed in some informal language into a relational structure (see figure 2).
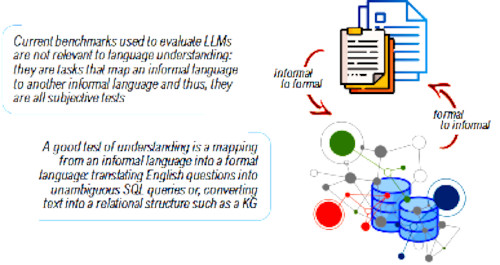
Figure 2. Mapping from an informal language to a formal language (or vice versa)
is a good test for linguistic competency since such mappings can be objectively evaluated.
Evaluating LLMs for their linguistic competency on these tasks is an objective task since there are no degrees of freedom in this mapping/interpretation. In translating an English query into an unambiguous SQL query, for example, we cannot make any mistake since that would result in the wrong query and thus in the wrong answer. Similarly, in translating informal language into a formal language (e.g., English to relations in a knowledge graph) the mapping would also fail if there was no full understanding of the informal language. For example, an engine that is performing the mapping in figure 2 must understand that the implicit relation between ‘plastic’ and ‘factory’ in "plastic factory" is that ‘plastic’ is the product produced by the ‘factory’ while the relation between ‘plastic’ and ‘knife’ in "plastic knife" is that ‘plastic’ is the material that the knife is made of (see figure 3).
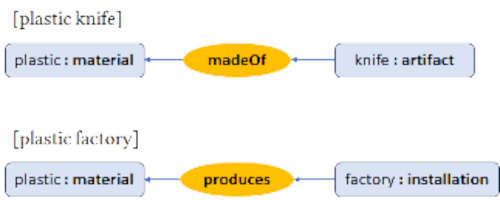
Figure 3. Mapping from informal to formal language (and vice versa)
is a true test for linguistic competency since such tests can be objectively evaluated.
Another example that shows why mappings between informal and formal languages are true tests for linguistic competency is an example where a full understanding of the informal text requires making inferences and ‘discovering’ information that is not explicitly stated in the text, as in extracting all the entities and relations that are implied by the following text:
It was fun being in Barcelona yesterday.
The city was celebrating its win over Real Madrid,
as it was also getting ready to vote on independence.
A simple test on any of the popular LLMs shows how these massive statistical hashtables cannot make inferences to discover information that is not explicitly stated in the text. The proper fragment of a knowledge graph that corresponds to the above text must ‘discover’ that Barcelona above is used to refer three different types of entities: the city (geographic location, where I was), the football team (that won over Real Madrid), and the (voting) citizens of Barcelona (that were getting ready to vote on independence). LLMs, in all their variations, fail completely on such tasks.
3. Concluding Remarks
A lot of ink has been spilled on all kinds of evaluations of LLMs on various linguistic tasks, but we believe that most of these tasks are subjective in nature and thus there is no objective way to know that our LLMs ‘understand’ language at a level that can be relied upon in practical applications in the enterprise. What we suggest here is that useful tests should involve testing a mapping from informal languages (e.g., English) to a formal language (such as SQL or SPARQL), for example in translating English queries to unambiguous SQL queries, or properly extracting all the entities and relations that are implicit in some text. Subjective benchmarks might still be useful to evaluate how some tasks such as summarization, sentiment analysis, etc. perform, but these are not tests for linguistic competency.
Walid Saba is Senior Research Scientist at the Institute for Experiential AI at Northeastern University. He has published over 45 articles on AI and NLP, including an award-winning paper at KI-2008.
No entries found